Les activités clés de votre entreprise dépendent fortement de vos systèmes ICT ? Dans ce cas, mieux vaut bien vous protéger, mais aussi prévoir un plan de reprise d’activité (Disaster Recovery Plan) à toute épreuve afin de minimiser l’impact d’éventuels sinistres informatiques.
Même les systèmes TIC les mieux protégés ne sont pas totalement à l’abri de catastrophes — lesquelles ne doivent pas nécessairement prendre la forme d’une inondation ou d’un incendie pour avoir des conséquences désastreuses. Une erreur humaine, un virus, un système informatique corrompu, une cyberattaque, une panne de serveur, voire une simple coupure électrique peuvent également infliger des dommages substantiels à une organisation.
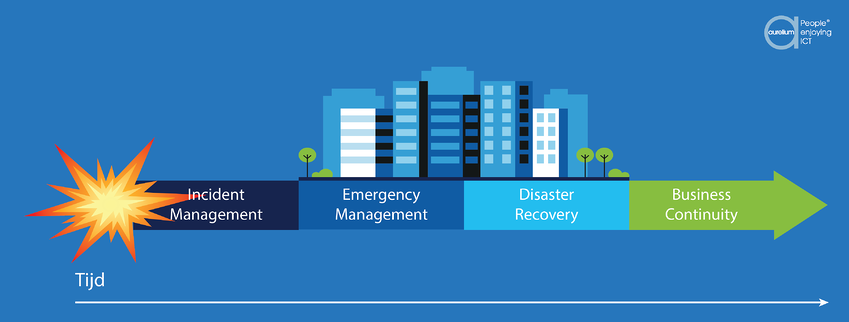
Qu’est-ce qu’un Disaster Recovery Plan ?
Un Disaster Recovery Plan (DRP ou plan de reprise d’activité) décrit l’approche à adopter en cas d’incidents ICT menaçant la continuité des activités, dans le but de minimiser leur impact négatif. Il s’agit d’une feuille de route indiquant étape par étape qui doit faire quoi et quand en cas de grave problème informatique.
Bien sûr, on ne sort pas un tel plan de sa manche. Une foule de préparatifs et de réflexions s’impose. Le DRP doit en outre être régulièrement actualisé.
Phase 1 : Préparation
La préparation s’articule en quatre éléments : une analyse des risques, une analyse de l’impact sur les activités, le Recovery Time Objective (objectif de temps de reprise) et le Recovery Point Objective (objectif de point de reprise).
Analyse des risques
En ce qui concerne les scénarios de risque, le monde de l’informatique tient essentiellement compte de la destruction (partielle) de l’organisation physique suite à une force majeure (inondation, incendie, tempêtes...) et de la perte de données ou de temps d’arrêt dus à un virus, une cyberattaque, une panne de courant, un vol ou encore une erreur humaine.
Dans le cadre de l’analyse de risques, nous évaluons l’impact de l’indisponibilité de certains services ou applications, et évaluons la probabilité d’un tel scénario. Pour ce faire, nous devons savoir exactement quels services et applications tournent sur les différentes parties de votre infrastructure informatique et leur emplacement.
Business Impact Analyse (analyse des incidences sur les activités)
Lors d’une Business Impact Analyse, nous évaluons la manière dont les différentes business units travaillent, quels processus reposent sur l’IT et quelles pourraient être les conséquences de certains risques sur ces processus et d’autres activités de l’entreprise.
Une liste de priorités est alors établie. Les risques susceptibles d’exercer un impact sur l’ensemble de l’organisation figureront certainement plus haut sur cette liste que ceux pesant sur une petite partie. Et les risques à même d’entraîner des pertes opérationnelles et financières seront sans doute mieux classés que les sinistres limités à la compétitivité ou à la réputation de l’entreprise.
L’analyse des incidences sur les activités donne une image claire de l’ensemble des coûts et répercussions possibles d’un type de crash spécifique. Nous devons ensuite déterminer dans quelle mesure les applications et services essentiels à l’entreprise doivent pouvoir résister à une éventuelle défaillance ainsi que le temps d’indisponibilité maximal acceptable. C’est seulement alors que nous pourrons envisager les options permettant d’accroître leur résistance et de réduire le temps d’interruption.
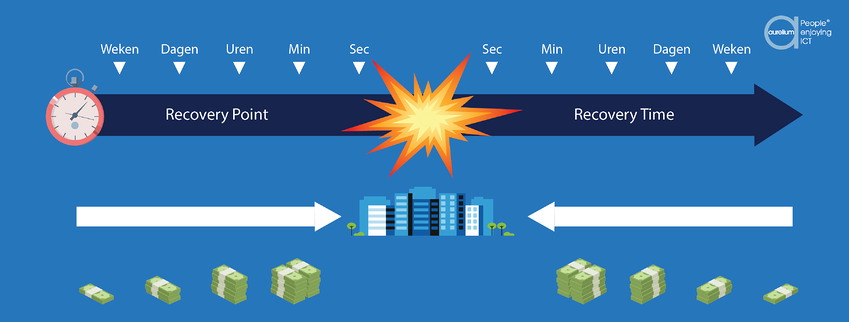
Détermination du Recovery Time Objective (objectif de temps de reprise)
Le Recovery Time Objective (RTO) est le délai dans lequel une fonction, un processus ou un service doit redevenir opérationnel après une panne, afin que l’entreprise puisse reprendre ses activités. C’est sur cette base que nous déterminons les mesures et budgets requis.
Si le RTO est estimé à cinq heures parce que l’entreprise ne survivrait pas à un arrêt plus long, l’entreprise devra procéder aux investissements nécessaires pour pouvoir restaurer efficacement les systèmes en question dans ce délai. Si le RTO est estimé à deux semaines, il suffira d’opter pour une solution de reprise moins rapide et plus économique.
Détermination du Recovery Point Objective (objectif de point de reprise)
Le Recovery Point Objective (RPO) décrit le moment où la quantité de données perdues dépasse le seuil autorisé maximum. Cet objectif est déterminé sur la base du temps qui s’écoule entre deux sauvegardes et de la quantité de données qui pourrait être perdue dans l’intervalle.
Dans nombre d’environnements ICT, une sauvegarde est programmée chaque nuit. Mais si le crash survient à la fin de la journée de travail ou pendant la nuit, avant le back-up programmé, il y a un risque réel de perdre les données de toute la journée.
L’organisation n’est alors plus en mesure de récupérer les données ou de les retraiter sans que l’entreprise en pâtisse lourdement ? Dans ce cas, le RPO doit être raccourci, avec plusieurs back-up par jour.
Phase 2 : Identification de l’environnement ICT
Pour pouvoir évaluer la vulnérabilité de certains services ou activités, vous devez savoir exactement comment se déroulent vos processus d’entreprise et quels composants fonctionnent sur quelle infrastructure ICT.
Dans ce contexte, nous examinons également les points suivants :
- Qu’est-ce qui est nécessaire pour faire tourner les différents systèmes ?
- La panne d’un système peut-elle en affecter d’autres ?
- Chaque système a-t-il été dédoublé et sécurisé ?
- Quels Service Level Agreements et garanties sont en vigueur ?
- A-t-on réalisé et conservé suffisamment de back-up pour chaque système ?
Phase 3 : Stratégie de reprise d’activité
Après les deux premières phases, nous sommes prêts à définir des actions et procédures concrètes à mettre en œuvre dans l’éventualité d’un crash.
Rôles et responsabilités
Qui doit et peut faire quoi en cas de sinistre ? Créez un tableau reprenant :
- Les coordonnées des membres de la Disaster Recovery Team ;
- Le rôle et la responsabilité de chaque membre ;
- Les plafonds budgétaires (pour l’achat d’équipements nécessaires, par exemple) ;
- Les limitations de leur autorité en cas d’incident.
Incident Response
Le DRP indique qui évaluera initialement la gravité de la situation, informera les personnes concernées et tentera de maîtriser l’incident.
Plan d’activation
Sur la base de cette première réaction, les membres sollicités décideront quelles parties du DRP doivent être mises en œuvre. Le PRA décrit en détail et pas à pas comment le processus d’entreprise ou l’élément de réseau affecté peut être rétabli avec un maximum de vitesse et d’efficacité, et si un autre système peut assumer (temporairement) ses tâches.
Documentation
Un DRP contient encore d’autres informations potentiellement utiles, comme les coordonnées des fournisseurs, les procédures de reprise spécifiées par les fournisseurs, les inventaires des applications et systèmes, les descriptifs et schémas des réseaux, les contrats et SLAs, etc.
Phase 4 : Tests et évaluation
Tests
Testez régulièrement votre DRP et ajustez-le si vous constatez que les procédures définies sont inadéquates, par exemple parce qu’elles ne respectent pas les RTO ou RPO.
Actualisations
Actualisez votre DRP au moins une fois par an. Un PRA dont les informations relatives aux contacts et contrats sont obsolètes vous laissera tomber au moment de vérité. Pensez également à l’impact de tout nouvel investissement informatique sur votre PRA : faut-il actualiser le plan en conséquence ?
Business Continuity Plan
Le DRP fait partie du Business Continuity Plan (BCP, plan de continuité des activités), qui regroupe toutes les démarches garantissant la continuité des activités ainsi que la disponibilité des fonctions essentielles pour les clients, les fournisseurs et les autres parties prenantes.
Besoin d’aide pour élaborer un DRP solide ? Contactez-nous vite !



